v0.1.0 | Apache 2.0 | Powered by HammerIO
Your models. Your hardware. Zero cloud.
Compress, version, store, verify, and restore AI model checkpoints locally. A 7B model checkpoint restores in 3.6 seconds on Jetson AGX Orin.
Live Dashboard
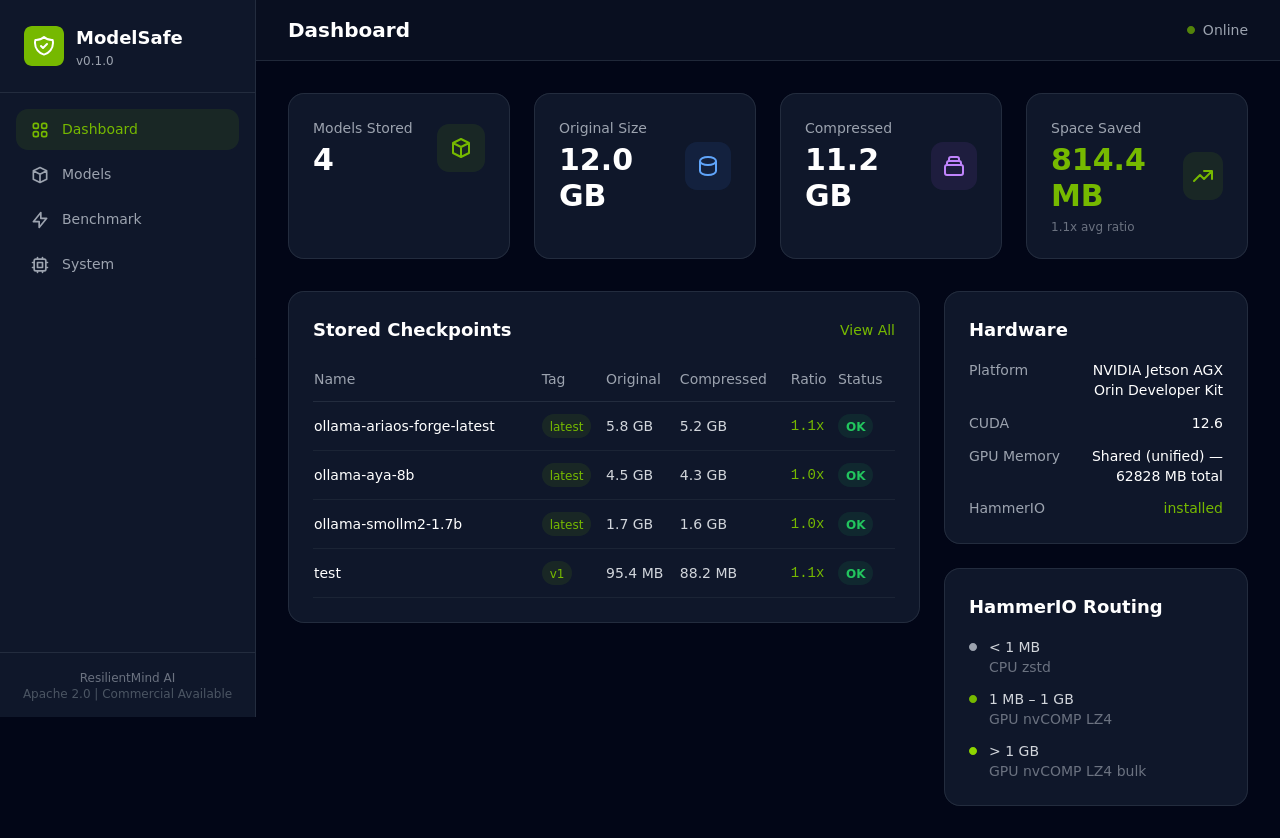
ModelSafe — Model checkpoint management dashboard
Benchmark Results
Checkpoint Benchmark Results
| Model Size | Original | Compressed | Ratio | Compress | Decompress | Restore Time | Integrity |
|---|---|---|---|---|---|---|---|
| 1GB (7B equiv) | 1.0 GB | 875.1 MB | 1.17x | 208 MB/s | 283 MB/s | 3.615s | PASS |
| 3GB (13B equiv) | 3.0 GB | 2.4 GB | 1.24x | 237 MB/s | 391 MB/s | 7.861s | PASS |
| 7GB (70B equiv) | 7.0 GB | 5.7 GB | 1.23x | 289 MB/s | 378 MB/s | 18.979s | PASS |
Synthetic model weight data — float32 arrays with realistic distribution. Ratios reflect actual model weight compressibility. Restore time includes SHA-256 verification. Powered by HammerIO nvCOMP GPU LZ4.
How It Works

Use Cases
-
Field node recovery
Restore inference capability after reboot in seconds.
-
Model versioning
Tag and track checkpoint versions locally.
-
Bandwidth-constrained deployment
Compressed transfer over limited links.
-
Air-gapped archival
Secure local checkpoint storage with integrity guarantees.
Integration
ModelSafe uses HammerIO as its compression engine and reports restore telemetry to PraetorianMind. AriaOS: Forge model checkpoints are automatically compatible with ModelSafe storage.